Wie unser Gehirn Fremdsprachen lernt
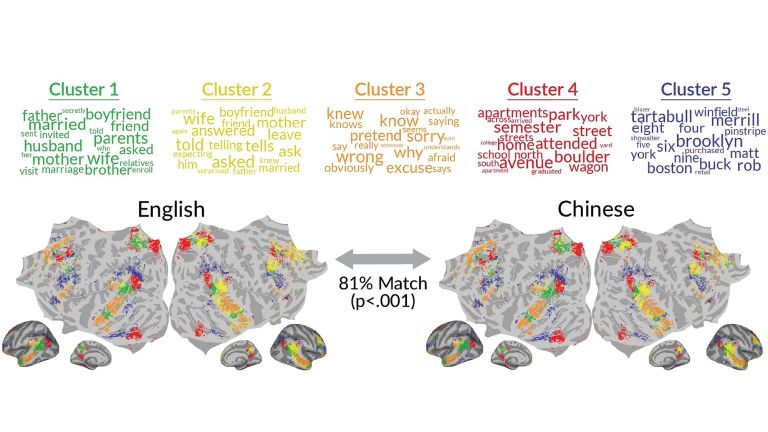
Wenn unser Gehirn Fremdsprachen lernt, legt es die neu erworbenen Worte und Zusammenhänge in den Gehirnregionen ab, in denen der Begriff auch in der Muttersprache abgespeichert wurde. Zwischen Fremdsprache und Muttersprache treten allerdings kleine Verschiebungen auf, wenn man sich die Orte im Gehirn und die einzelnen Worte ganz genau anschaut. Diese Verschiebungen sind für die untersuchte Sprachenkombination „Muttersprache Chinesisch, Fremdsprache Englisch“ bei verschiedenen Personen sehr ähnlich. Das sind die zentralen Ergebnisse einer Studie des Fachgebiets „Sprache und Kommunikation in biologischen und künstlichen Systemen“ der TU Berlin in Zusammenarbeit mit Forscher*innen der University of California, Berkeley, die jetzt in der Fachzeitschrift PNAS veröffentlicht wurde. Leiterin des Fachgebiets ist Prof. Dr. Fatma Deniz, Vizepräsidentin für Digitalisierung und Nachhaltigkeit sowie designierte Präsidentin der TU Berlin. Die Resultate erweitern grundlegend unser Verständnis darüber, wie Sprachenlernen beim Menschen funktioniert und vereinen zwei sich scheinbar widersprechende Theorien in einem neuen Modell.
Veröffentlicht: 25.03.2026
Konkret geht es hier um zwei Theorien, wie sich eine neu erlernte Sprache im Gehirn verankert. Wird ein bestimmter Begriff in der neuen Sprache in der gleichen Gehirnregion abgelegt, in der er auch in der Muttersprache abgespeichert wurde? Oder etabliert er sich in einer ganz anderen Gehirnregion?
Neurowissenschaftliche Untersuchungen zum Sprachenlernen widersprachen sich
„Sowohl für die eine wie für die andere Hypothese gab es in der Vergangenheit experimentelle Belege“, sagt Deniz. „Da lag es für uns nahe, dass in irgendeiner Weise eine Mischung aus beiden Konzepten der Wahrheit vielleicht am nächsten kommt.“ Um diese Vermutung zu testen, untersuchte das Team um Fatma Deniz insgesamt sechs Personen intensiv in einem Hirnscanner an der University of California, Berkeley, der mit der Methode der Magnetresonanztomographie (MRT) arbeitet. Alle Personen hatten Chinesisch als Muttersprache und Englisch als Zweitsprache später dazu erlernt. Im MRT-Gehirnscan haben sie insgesamt über mehrere Stunden sowohl auf Chinesisch wie auch auf Englisch verschiedene Geschichten gelesen, in denen Menschen von ihren persönlichen Erlebnissen zu ganz unterschiedlichen Themen erzählen. Bei jedem gelesenen Wort konnten die Forscher*innen anhand der MRT-Daten erkennen, in welcher Region das Gehirn beim Lesen des Wortes besonders stark durchblutet wird. Es ist plausibel anzunehmen, dass dies auch der Ort ist, an dem das Wort beim Lernen der Sprache verankert wurde.
Magnetresonanztomographie
Magnetresonanztomographie/-/magnetic resonance imaging
Ein bildgebendes Verfahren, das Mediziner zur Diagnose verschiedener Erkrankungen und Fehlbildungen in unterschiedlichen Geweben oder Organen des Körpers einsetzen. Die Methode wird umgangssprachlich auch Kernspin genannt. Sie beruht darauf, dass die Kerne mancher Atome einen Eigendrehimpuls besitzen, der sich im starken Magnetfeld ausrichtet. Diese Eigenschaft trifft unter anderem auf Wasserstoff zu. Deshalb können Gewebe, die viel Wasser enthalten, besonders gut dargestellt werden. Abkürzung: MRT.
Semantische Repräsentationen: Welche Worte werden oft zusammen genannt?
Um im Detail untersuchen zu können, wie die Sprache im Gehirn beim Lesen verarbeitet wird, sind die Forscher*innen aus Berlin und Berkeley systematisch vorgegangen. Zum einen haben sie das Gehirn in „Volumen-Pixel“ aufgeteilt, sogenannte Voxel (volumetric pixel), also kleine räumliche Bereiche. Zum anderen haben sie die Worte aus den Geschichten in Themengruppen klassifiziert, und zwar mit Hilfe von Sprachmodellen aus der Künstlichen Intelligenz (das bekannteste ist ChatGPT, es wurden hier aber andere Sprachmodelle verwendet). Bei diesen „semantischen Repräsentationen“ geht es darum, welche Worte mit welcher Wahrscheinlichkeit in einem engen Zusammenhang miteinander verwendet werden. „Wir müssen hier also sehr komplexe statistische Analysen durchführen, um zu aussagekräftigen Ergebnissen zu gelangen“, so Deniz.
Intelligenz
Intelligenz/-/intelligence
Sammelbegriff für die kognitive Leistungsfähigkeit des Menschen. Dem britischen Psychologen Charles Spearman zufolge sind kognitive Leistungen, die Menschen auf unterschiedlichen Gebieten erbringen, mit einem Generalfaktor (g-Faktor) der Intelligenz korreliert. Demnach lasse sich die Intelligenz durch einen einzigen Wert ausdrücken. Hierzu hat u.a. der US-Amerikaner Howard Gardner ein Gegenkonzept entwickelt, die „Theorie der multiplen Intelligenzen“. Dieser Theorie zufolge entfaltet sich die Intelligenz unabhängig voneinander auf folgenden acht Gebieten: sprachlich-linguistisch, logisch-mathematisch, musikalisch-rhythmisch, bildlich-räumlich, körperlich-kinästhetisch, naturalistisch, intrapersonal und interpersonal.
Same same, but different
Das Resultat der Untersuchungen: In jedem Voxel werden jeweils verschiedene Themengebiete mit einer gewissen Wahrscheinlichkeit verarbeitet – in einem Voxel beispielsweise mit einer Wahrscheinlichkeit von 80 Prozent Worte, die eine räumliche Orientierung ausdrücken, wie „Süden“, „vorne“, „Wohnung“ und ähnliches. Im gleichen Voxel werden aber auch ganz andere Themen verarbeitet, zum Beispiel mit einer Wahrscheinlichkeit von 20 Prozent Worte im Themenfeld „Fahrzeuge“. „Was wir nun einerseits finden ist, dass diese Oberthemen und die zugehörigen Wahrscheinlichkeiten für jedes Voxel gleichbleiben, egal, ob die Person einen chinesischen oder einen englischen Text gelesen hat. Jedes Voxel ‚interessiert‘ sich also quasi für die gleichen Dinge, unabhängig von der verwendeten Sprache“, berichtet Fatma Deniz. „Schauen wir aber genau hin, bei welchen Worten welches Voxel anspringt, stellen wir Verschiebungen innerhalb dieser gleichbleibenden Oberthemen fest.“ So verarbeite beispielsweise im Chinesischen ein Voxel beim Oberthema „räumliche Orientierung“ vor allem Worte, die mit Beziehungen zu tun haben wie „ankommen“ oder „zusammen“. Beim englischen Text dagegen verschiebe sich dies dann zu Worten, die mehr mit Ausrichtungen und Zahlen zu tun haben wie „Norden“ oder „sieben (Kilometer)“.
Trickreiche Überprüfung der Resultate
Das Forscher*innenteam ist sich trotz der kleinen Anzahl von sechs Proband*innen sehr sicher, dass seine Ergebnisse valide sind. Dies liegt am speziellen Design ihres Experiments, bei dem für die Proband*innen Modelle mit Hilfe des Maschinellen Lernens trainiert wurden, um die Messergebnisse zu reproduzieren. Die Anpassung der Modellparameter wurde hierbei zunächst nur mit vier Proband*innen vorgenommen. Diese Modelle konnten dann sowohl die Themenverteilung der Voxel wie auch die oben beschriebenen Verschiebungen bei den zwei anderen Proband*innen genau vorhersagen.
Vorherige Untersuchungen wurden in die Studie einbezogen
Ein weiterer Befund stützt ebenfalls die Resultate der Studie: Bereits in einem vorherigen Experiment hatte die Arbeitsgruppe um Fatma Deniz Proband*innen mit den gleichen Texten auf Englisch im Hirnscan – dort waren es allerdings englische Muttersprachler*innen und es ging um den Unterschied zwischen dem Lesen und dem Hören von Texten. „Wir konnten ähnliche semantische Verschiebungen feststellen bei den englischen Texten zwischen den Scans der englischen Muttersprachler*innen und den Proband*innen im neuen Experiment, die Englisch als zweite Fremdsprache gelernt hatten. Das deutet darauf hin, dass diese Verschiebungen keinen spezifischen Unterschied zwischen Englisch und Chinesisch darstellen, sondern möglicherweise einen Unterschied zwischen Muttersprache und Fremdsprache.“
Experimente mit weiteren Sprachkombinationen in Planung
Die Wissenschaftler*innen aus Deutschland und den USA wollen nun ihre Experimente auf andere Sprachen ausweiten, etwa auf solche, die im Gegensatz zu Chinesisch und Englisch wesentlich näher beieinander liegen wie etwa Italienisch und Spanisch. Auch das umgedrehte Experiment zur vorliegenden Studie wollen sie in der Zukunft durchführen, also mit Proband*innen arbeiten, deren Muttersprache Englisch und die erste Fremdsprache Chinesisch ist. „Mit der in unseren Augen geglückten Fusion der beiden konträren Hypothesen in der neurowissenschaftlichen Sprachforschung sind wir einen guten Schritt weitergekommen in der Frage, wie Sprachenlernen funktioniert“, erklärt Fatma Deniz. Die Erkenntnisse könnten gegebenenfalls auch bei der Rehabilitation von Aphasie-Patient*innen helfen, die nach einer Beschädigung bestimmter Gehirnregionen gesprochene oder geschriebene Sprache nicht mehr richtig ausdrücken und verstehen können. „Generell bildet unsere Grundlagenforschung eine wichtige Basis für alle, die das Verstehen und Lernen von Fremdsprachen und damit allgemein die Kommunikation unter Menschen verbessern wollen.“
